

A New Extension of the Kumaraswamy Generated Family of Distributions with Applications to Real Data



Abstract
:1. Introduction
2. The NEKwG Family
2.1. Definition
2.2. Some Special Distributions
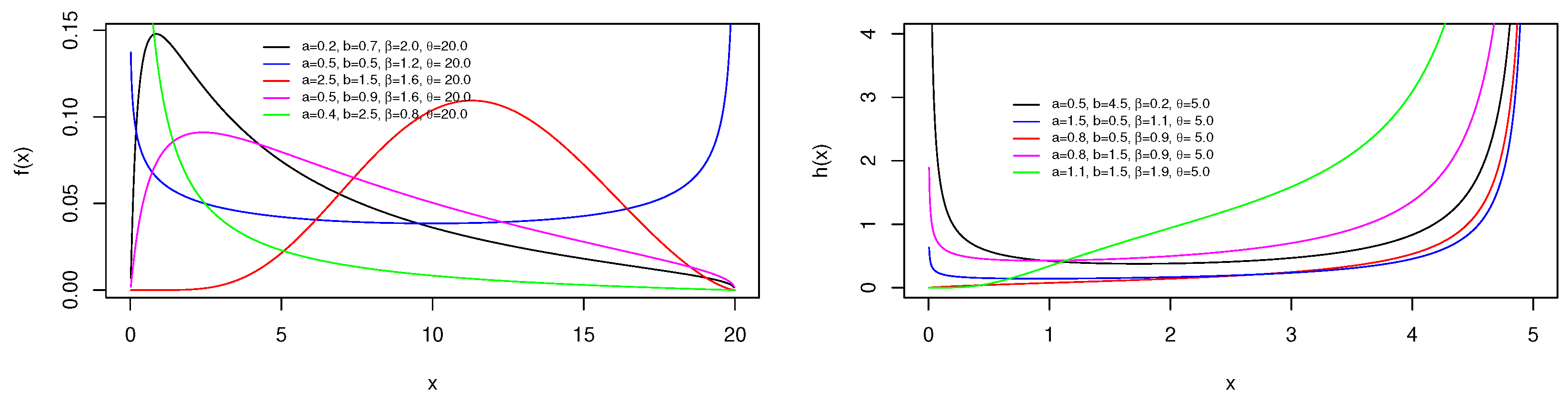
2.2.1. New Extended Kw Uniform (NEKwU) Distribution
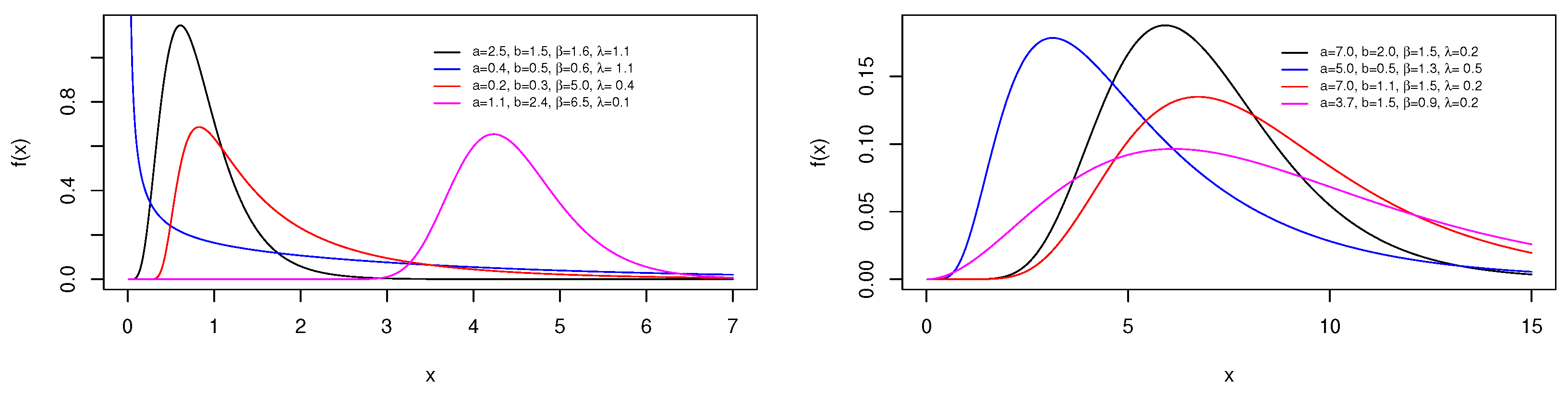
2.2.2. New Extended Kw Exponential (NEKwE) Distribution
3. Mathematical Developments
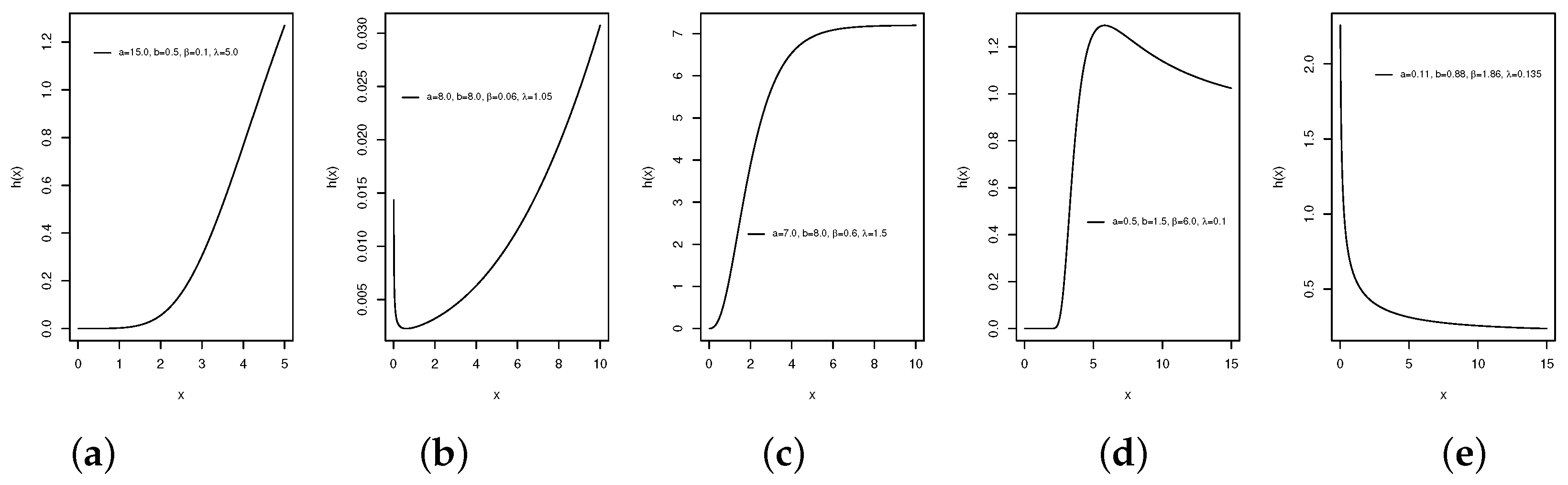
3.1. Asymptotic Results
- As , we have
- As , we havewhere denotes the hrf associated to the baseline distribution.
3.2. Expansions and Approximations
3.3. Moments and Entropy
- Moments are significant theoretical measures because they provide an alternative way to fully and uniquely specify a characteristic of a probability distribution, such as the central tendency, deviations, skewness, and kurtosis. Incomplete moments aid in obtaining mean deviations and some important reliability measures, such as moments of residual life. Let X be a random variable (rv) with a distribution belonging to the KwG family.
- The central moment of X can be expressed and approximated asFrom it, we can derive the mean (), variance (), and other raw-moment composed measures.
- The incomplete moment of X can be expressed and approximated asBased on it, we can derive various mean deviations and reverse residual life functions.
Remark 1.In the special case where β is an integer greater to 1 (implying that is a positive integer for any positive integer j), we can express in a series form to further express . This will allow us to obtain the mean, variance, and other possible moments in series form. The following lemma is required: logarithmic series representation.Lemma 3.Hence, we can writewhere and for . Therefore, by the binomial formula, we haveBy virtue of Lemma 3, we obtainwhere and for . Thus,where . As a result, from (8) at , can be expressed aswhere . In particular, the moments of X can be expressed asthus,where is the moment associated to a random variable Y that follows the exponentiated baseline distribution with cdf . In particular, for our proposed NEKwE and NEKwU distributions, the expression of are available in [52,53], respectively; the computation of the first integral in (11) follow similar way to the . In Table 2 and Table 3, we provide some possible numerical values of some moments from (9) computed using theintegratefunction inR3.5.3software [54]. - Entropy in information theory is directly analogous to entropy in statistical thermodynamics. The average level of information or uncertainty in a random variable or system is defined as its entropy. One can see [55,56].Here, we discuss the Rényi entropy of the new model. The Rényi entropy can be derived from the following formula:where and , and we can approximate the expectation term asAn approximation of follows by substitution. This entropy measures the amount of information contained in X. Another useful entropy, the Shannon entropy defined by , is a special case of the Rényi entropy when .
3.4. Order Statistics and Applications
4. Inference
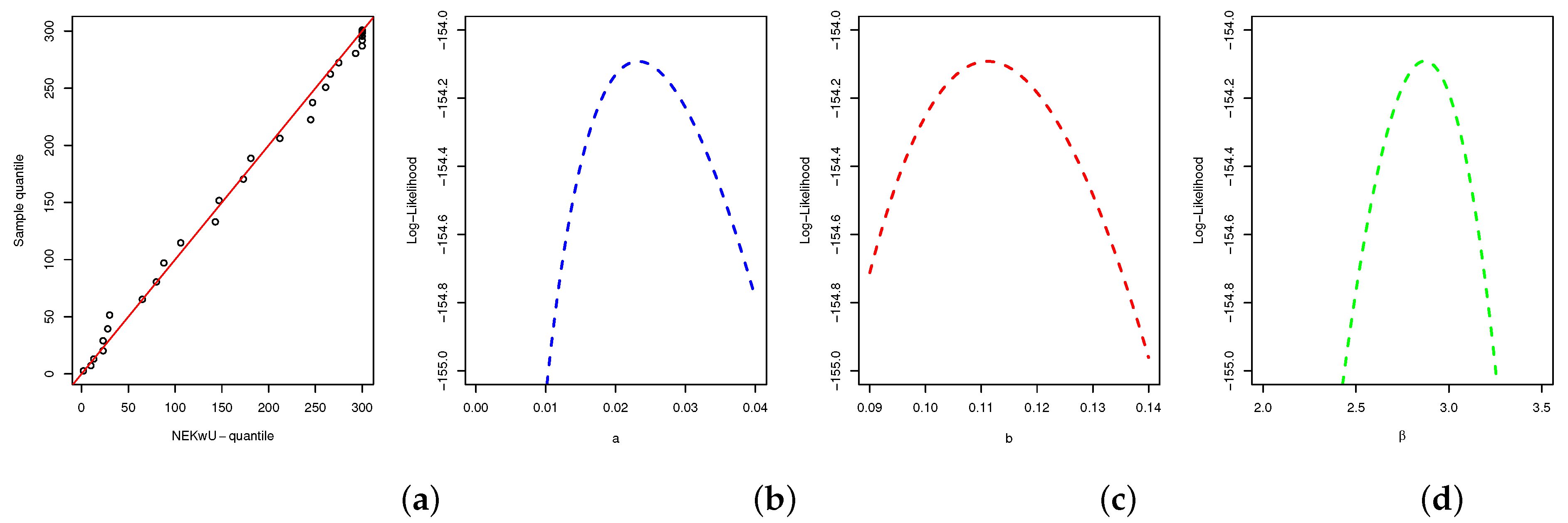
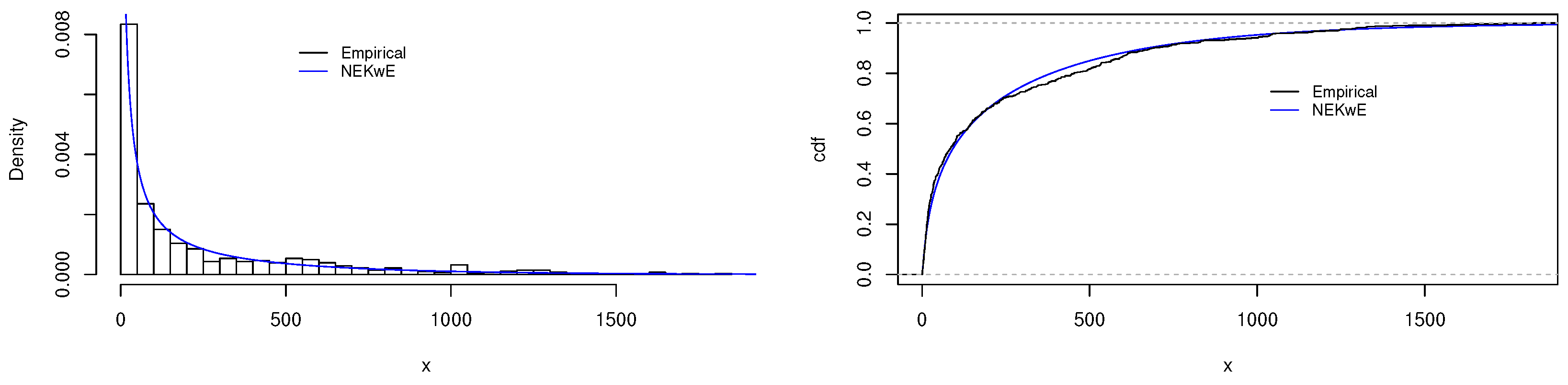
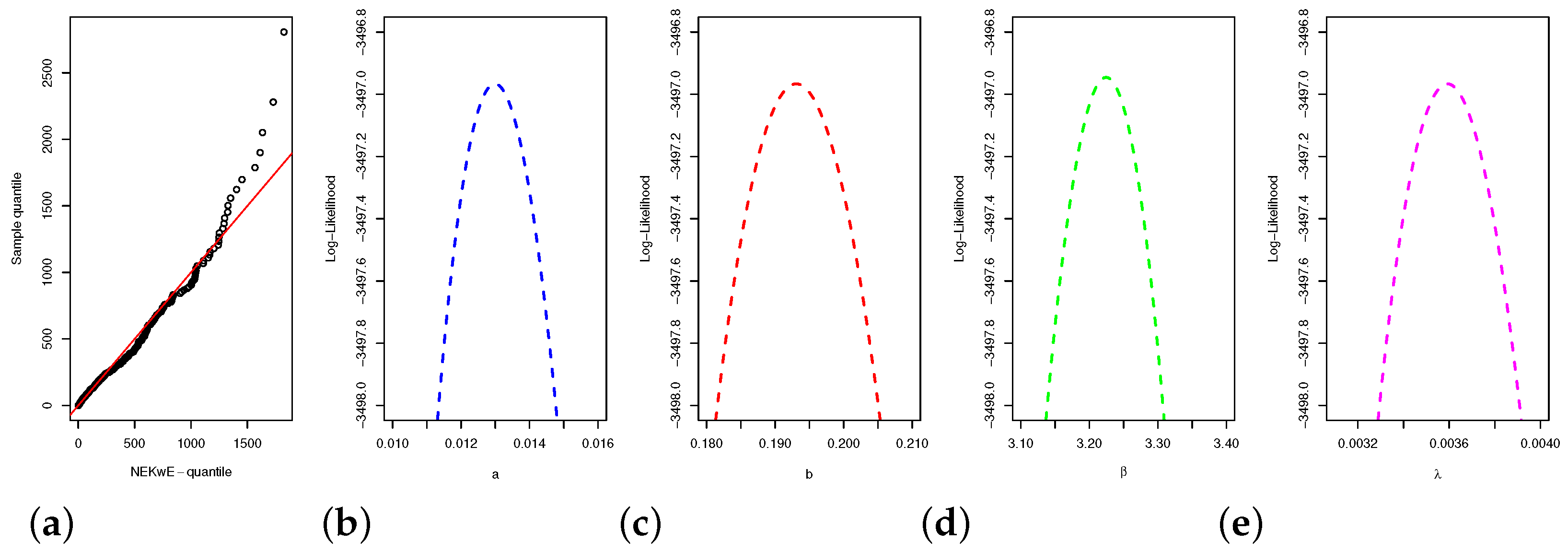
4.1. Maximum Likelihood Estimation Method
4.2. Least-Squares Estimation Method
4.3. Bayes Estimation Method
4.4. Simulation
- Choose the sample size n, replication number M, and the values of parameters ;
- Generate random sample with following the uniform distribution, ;
- Generate random sample with following the NEKwE distribution, , from (7);
- Calculate the MLEs, LSEs, and BEs of the parameters of the NEKwE distribution from the simulated data;
- Repeat steps , M times;
- Calculate the average bias and the average MSE for each parameter.
5. Real Data Illustrations
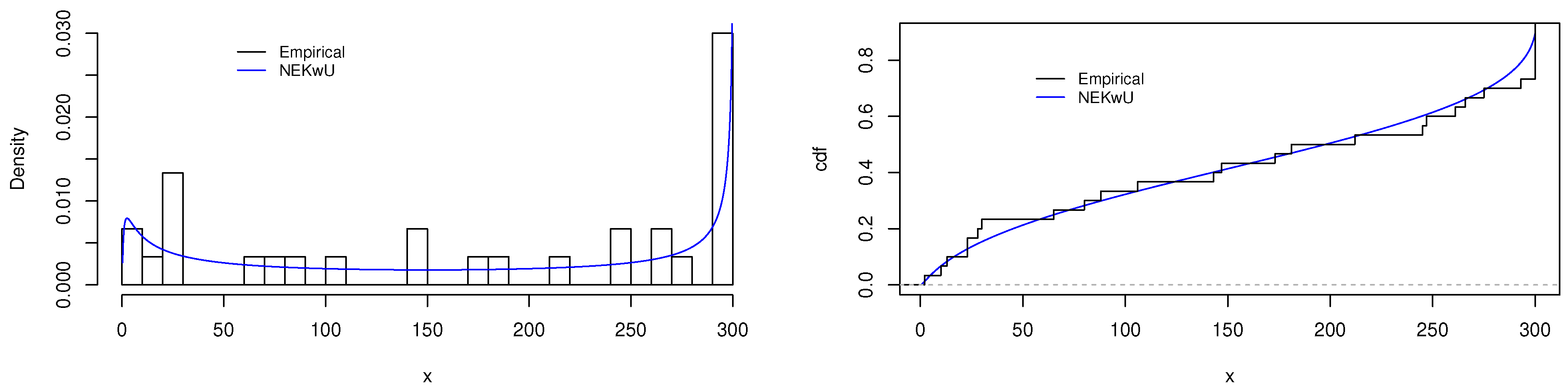
5.1. First Data Illustration
5.2. Second Data Illustration
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kumaraswamy, P. A generalized probability density function for double-bounded random processes. J. Hydrol. 1980, 46, 79–88. [Google Scholar] [CrossRef]
- Jones, M. Kumaraswamy’s distribution: A beta-type distribution with some tractability advantages. Stat. Methodol. 2009, 6, 70–81. [Google Scholar] [CrossRef]
- Ponnambalam, K.; Seifi, A.; Vlach, J. Probabilistic design of systems with general distributions of parameters. Int. J. Circuit Theory Appl. 2001, 29, 527–536. [Google Scholar] [CrossRef]
- Nadarajah, S. On the distribution of Kumaraswamy. J. Hydrol. 2008, 348, 568–569. [Google Scholar] [CrossRef]
- Mitnik, P.A.; Baek, S. The Kumaraswamy distribution: Median-dispersion re-parameterizations for regression modeling and simulation-based estimation. Stat. Pap. 2013, 54, 177–192. [Google Scholar] [CrossRef]
- Pumi, G.; Rauber, C.; Bayer, F.M. Kumaraswamy regression model with Aranda-Ordaz link function. Test 2020, 29, 1051–1071. [Google Scholar] [CrossRef]
- Hamedi-Shahraki, S.; Rasekhi, A.; Yekaninejad, M.S.; Eshraghian, M.R.; Pakpour, A.H. Kumaraswamy regression modeling for Bounded Outcome Scores. Pak. J. Stat. Oper. Res. 2021, 17, 79–88. [Google Scholar] [CrossRef]
- Sundar, V.; Subbiah, K. Application of double bounded probability density function for analysis of ocean waves. Ocean Eng. 1989, 16, 193–200. [Google Scholar] [CrossRef]
- Seifi, A.; Ponnambalam, K.; Vlach, J. Maximization of manufacturing yield of systems with arbitrary distributions of component values. Ann. Oper. Res. 2000, 99, 373–383. [Google Scholar] [CrossRef]
- Fletcher, S.; Ponnambalam, K. Estimation of reservoir yield and storage distribution using moments analysis. J. Hydrol. 1996, 182, 259–275. [Google Scholar] [CrossRef]
- Ganji, A.; Ponnambalam, K.; Khalili, D.; Karamouz, M. Grain yield reliability analysis with crop water demand uncertainty. Stoch. Environ. Res. Risk Assess. 2006, 20, 259–277. [Google Scholar] [CrossRef]
- Garg, M. On Generalized Order Statistics From Kumaraswamy Distribution. Tamsui Oxf. J. Math. Sci. (TOJMS) 2009, 25, 153–166. [Google Scholar]
- Lemonte, A.J. Improved point estimation for the Kumaraswamy distribution. J. Stat. Comput. Simul. 2011, 81, 1971–1982. [Google Scholar] [CrossRef]
- Gholizadeh, R.; Khalilpor, M.; Hadian, M. Bayesian estimations in the Kumaraswamy distribution under progressively type II censoring data. Int. J. Eng. Sci. Technol. 2011, 3, 47–65. [Google Scholar] [CrossRef]
- Sindhu, T.N.; Feroze, N.; Aslam, M. Bayesian analysis of the Kumaraswamy distribution under failure censoring sampling scheme. Int. J. Adv. Sci. Technol. 2013, 51, 39–58. [Google Scholar]
- Nadar, M.; Papadopoulos, A.; Kızılaslan, F. Statistical analysis for Kumaraswamy’s distribution based on record data. Stat. Pap. 2013, 54, 355–369. [Google Scholar] [CrossRef]
- Nadar, M.; Kızılaslan, F.; Papadopoulos, A. Classical and Bayesian estimation of P(Y<X) for Kumaraswamy’s distribution. J. Stat. Comput. Simul. 2014, 84, 1505–1529. [Google Scholar]
- Nadar, M.; Kızılaslan, F. Classical and Bayesian estimation of P(X<Y) using upper record values from Kumaraswamy’s distribution. Stat. Pap. 2014, 55, 751–783. [Google Scholar]
- Dey, S.; Mazucheli, J.; Nadarajah, S. Kumaraswamy distribution: Different methods of estimation. Comput. Appl. Math. 2018, 37, 2094–2111. [Google Scholar] [CrossRef]
- Ahmad, Z.; Hamedani, G.G.; Butt, N.S. Recent developments in distribution theory: A brief survey and some new generalized classes of distributions. Pak. J. Stat. Oper. Res. 2019, 15, 87–110. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; de Castro, M. A new family of generalized distributions. J. Stat. Comput. Simul. 2011, 81, 883–898. [Google Scholar] [CrossRef]
- Ahmed, M.A.; Mahmoud, M.R.; ElSherbini, E.A. The new Kumaraswamy Kumaraswamy family of generalized distributions with application. Pak. J. Stat. Oper. Res. 2015, 11, 159–180. [Google Scholar] [CrossRef]
- Alizadeh, M.; Tahir, M.; Cordeiro, G.M.; Mansoor, M.; Zubair, M.; Hamedani, G. The Kumaraswamy Marshal-Olkin family of distributions. J. Egypt. Math. Soc. 2015, 23, 546–557. [Google Scholar] [CrossRef]
- Afifya, A.Z.; Cordeiro, G.M.; Yousof, H.M.; Nofal, Z.M.; Alzaatreh, A. The Kumaraswamy transmuted-G family of distributions: Properties and applications. J. Data Sci. 2016, 14, 245–270. [Google Scholar] [CrossRef]
- Hassan, A.S.; Elgarhy, M. Kumaraswamy Weibull-generated family of distributions with applications. Adv. Appl. Stat. 2016, 48, 205. [Google Scholar] [CrossRef]
- Chakraborty, S.; Handique, L. Properties and data modelling applications of the Kumaraswamy generalized Marshall-Olkin-G family of distributions. J. Data Sci. 2017, 605, 620. [Google Scholar] [CrossRef]
- Nofal, Z.M.; Altun, E.; Afify, A.Z.; Ahsanullah, M. The generalized Kumaraswamy-G family of distributions. J. Stat. Theory Appl. 2019, 18, 329–342. [Google Scholar] [CrossRef]
- El-Sherpieny, E.S.; Elsehetry, M. Kumaraswamy type I half logistic family of distributions with applications. Gazi Univ. J. Sci. 2019, 32, 333–349. [Google Scholar]
- Silva, R.; Gomes-Silva, F.; Ramos, M.; Cordeiro, G.; Marinho, P.; De Andrade, T.A. The exponentiated Kumaraswamy-G Class: General properties and application. Rev. Colomb. De Estadística 2019, 42, 1–33. [Google Scholar] [CrossRef]
- Tahir, M.H.; Hussain, M.A.; Cordeiro, G.M.; El-Morshedy, M.; Eliwa, M.S. A new Kumaraswamy generalized family of distributions with properties, applications, and bivariate extension. Mathematics 2020, 8, 1989. [Google Scholar] [CrossRef]
- Chakraborty, S.; Handique, L.; Jamal, F. The Kumaraswamy Poisson-G family of distribution: Its properties and applications. Ann. Data Sci. 2020, 9, 229–247. [Google Scholar] [CrossRef]
- El-Morshedy, M.; Tahir, M.H.; Hussain, M.A.; Al-Bossly, A.; Eliwa, M.S. A New Flexible Univariate and Bivariate Family of Distributions for Unit Interval (0, 1). Symmetry 2022, 14, 1040. [Google Scholar] [CrossRef]
- Ramos, M.W.A.; Marinho, P.R.D.; Cordeiro, G.M.; da Silva, R.V.; Hamedani, G. The Kumaraswamy-G Poisson family of distributions. J. Stat. Theory Appl. 2015, 14, 222–239. [Google Scholar] [CrossRef]
- Handique, L.; Chakraborty, S. A new beta generated Kumaraswamy Marshall-Olkin-G family of distributions with applications. Malays. J. Sci. 2017, 36, 157–174. [Google Scholar] [CrossRef]
- Handique, L.; Chakraborty, S. The Beta generalized Marshall-Olkin Kumaraswamy-G family of distributions with applications. Int. J. Agricult. Stat. Sci 2017, 13, 721–733. [Google Scholar]
- Handique, L.; Chakraborty, S.; Hamedani, G. The Marshall-Olkin-Kumaraswamy-G family of distributions. J. Stat. Theory Appl. 2017, 16, 427–447. [Google Scholar] [CrossRef][Green Version]
- Handique, L.; Chakraborty, S.; Ali, M.M. Beta Generated Kumaraswamy-G Family of Distributions. Pak. J. Stat. 2017, 33, 467–490. [Google Scholar]
- Alshkaki, R. A generalized modification of the Kumaraswamy distribution for modeling and analyzing real-life data. Stat. Optim. Inf. Comput. 2020, 8, 521–548. [Google Scholar] [CrossRef]
- Selim, M.A. The Distributions of Beta-Generated and Kumaraswamy-Generalized Families: A Brief Survey. Figshare 2020, 1–19. [Google Scholar] [CrossRef]
- Muhammad, M.; Liu, L. A new extension of the beta generator of distributions. Math. Slovaca 2022, 72, 1319–1336. [Google Scholar] [CrossRef]
- Muhammad, M.; Liu, L.; Abba, B.; Muhammad, I.; Bouchane, M.; Zhang, H.; Musa, S. A New Extension of the Topp–Leone-Family of Models with Applications to Real Data. Ann. Data Sci. 2022, 10, 225–250. [Google Scholar] [CrossRef]
- Bakouch, H.; Chesneau, C.; Nauman Khan, M. The Extended Odd Family of Probability Distributions with Practice to a Submodel. Filomat 2019, 33, 3855–3867. [Google Scholar] [CrossRef]
- Elmorshedy, M.; Eliwa, M.S. The Odd Flexible Weibull-H Family of Distributions: Properties and Estimation with Applications to Complete and Upper Record Data. Filomat 2019, 33. [Google Scholar] [CrossRef]
- Gomes-Silva, F.; Ramos, M.; Percontini, A.; Venâncio, R.; Cordeiro, G. The Odd Lindley-G Family of Distributions. Austrian J. Stat. 2016, 46, 65–87. [Google Scholar] [CrossRef]
- Parzen, E. Quantile probability and statistical data modeling. Stat. Sci. 2004, 46, 652–662. [Google Scholar] [CrossRef]
- Bowley, A.L. Elements of Statistics; Number 8; King: Saint Julian’s, Malta, 1926. [Google Scholar]
- Moors, J. A quantile alternative for kurtosis. J. R. Stat. Soc. Ser. D 1988, 37, 25–32. [Google Scholar] [CrossRef]
- Muhammad, M.; Bantan, R.A.R.; Liu, L.; Chesneau, C.; Tahir, M.H.; Jamal, F.; Elgarhy, M. A New Extended Cosine—G Distributions for Lifetime Studies. Mathematics 2021, 9, 2758. [Google Scholar] [CrossRef]
- De Bruijn, N.G. Asymptotic Methods in Analysis; Courier Corporation: North Chelmsford, MA, USA, 1981; Volume 4. [Google Scholar]
- Chapling, R. Asymptotic Methods; University of Cambridge: Cambridge, UK, 2016. [Google Scholar]
- Gradshteyn, I.; Ryzhik, I.; Jeffrey, A.; Zwillinger, D. Table of Integrals, Series and Products, 7th ed.; Academic Press: New York, NY, USA, 2007. [Google Scholar]
- Gupta, R.D.; Kundu, D. Generalized exponential distribution: Different method of estimations. J. Stat. Comput. Simul. 2001, 69, 315–337. [Google Scholar] [CrossRef]
- Ramires, T.G.; Nakamura, L.R.; Righetto, A.J.; Pescim, R.R.; Telles, T.S. Exponentiated uniform distribution: An interesting alternative to truncated models. Semin. Exact Technol. Sci. 2019, 40, 107–114. [Google Scholar] [CrossRef]
- R Core Team. R. A Language and Environment for Statistical Computing, R Foundation for Statistical Computing; R Core Team: Vienna, Austria, 2019. [Google Scholar]
- Jaynes, E.T. Information theory and statistical mechanics. Phys. Rev. 1957, 106, 620. [Google Scholar] [CrossRef]
- Kamberaj, H.; Kamberaj, H. Information Theory and Statistical Mechanics. Mol. Dyn. Simulations Stat. Phys. Theory Appl. 2020, 343–369. [Google Scholar] [CrossRef]
- Barter, H.L. History and role of order statistics. Commun. Stat.-Theory Methods 1988, 17, 2091–2107. [Google Scholar] [CrossRef]
- Govindaraju, V.; Rao, C. Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2013. [Google Scholar]
- David, H.A.; Nagaraja, H.N. Order Statistics; John Wiley & Sons: Hoboken, NJ, USA, 2004. [Google Scholar]
- Greenberg, B.G.; Sarhan, A.E. Applications of order statistics to health data. Am. J. Public Health Nations Health 1958, 48, 1388–1394. [Google Scholar] [CrossRef]
- Dytso, A.; Cardone, M.; Rush, C. The most informative order statistic and its application to image denoising. arXiv 2021, arXiv:2101.11667. [Google Scholar]
- Schneider, H.; Barbera, F. 18 Application of order statistics to sampling plans for inspection by variables. In Order Statistics: Applications; Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 1998; Volume 17, pp. 497–511. [Google Scholar] [CrossRef]
- Arnold, B.C.; Balakrishnan, N.; Nagaraja, H.N. A First Course in Order Statistics; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 1992; Volume 54. [Google Scholar]
- Casella, G.; Berger, R. Statistical Inference; Brooks/Cole Pub.: Pacific Grove, CA, USA, 1990. [Google Scholar]
- Millar, R.B. Maximum Likelihood Estimation and Inference: With Examples in R, SAS and ADMB; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Plackett, R.L. A historical note on the method of least squares. Biometrika 1949, 36, 458–460. [Google Scholar] [CrossRef]
- Swain, J.J.; Venkatraman, S.; Wilson, J.R. Least-squares estimation of distribution functions in Johnson’s translation system. J. Stat. Comput. Simul. 1988, 29, 271–297. [Google Scholar] [CrossRef]
- Von Toussaint, U. Bayesian inference in physics. Rev. Mod. Phys. 2011, 83, 943. [Google Scholar] [CrossRef][Green Version]
- Greenland, S. Bayesian perspectives for epidemiological research. II. Regression analysis. Int. J. Epidemiol. 2007, 36, 195–202. [Google Scholar] [CrossRef]
- Chib, S.; Griffiths, W. Bayesian Econometrics; Emerald Group Publishing: Bradford, UK, 2008. [Google Scholar]
- Meredith, M.; Kruschke, J. HDInterval: Highest (Posterior) Density Intervals. R Package Version 0.1. 2016. Available online: https://cran.r-project.org/web/packages/HDInterval/index.html (accessed on 3 September 2022).
- Metropolis, N.; Rosenbluth, A.W.; Rosenbluth, M.N.; Teller, A.H.; Teller, E. Equation of state calculations by fast computing machines. J. Chem. Phys. 1953, 21, 1087–1092. [Google Scholar] [CrossRef]
- Hastings, W.K. Monte Carlo sampling methods using Markov chains and their applications. Biometrika 1970, 57, 97–109. [Google Scholar] [CrossRef]
- Gelfand, A.E.; Smith, A.F. Sampling-based approaches to calculating marginal densities. J. Am. Stat. Assoc. 1990, 85, 398–409. [Google Scholar] [CrossRef]
- Chen, M.H.; Shao, Q.M. Monte Carlo estimation of Bayesian credible and HPD intervals. J. Comput. Graph. Stat. 1999, 8, 69–92. [Google Scholar]
- Raftery, A.E.; Lewis, S. How Many Iterations in the Gibbs Sampler? Technical Report; Washington University Seattle Department of Statistics: St. Louis, MO, USA, 1991. [Google Scholar]
- Morris, T.P.; White, I.R.; Crowther, M.J. Using simulation studies to evaluate statistical methods. Stat. Med. 2019, 38, 2074–2102. [Google Scholar] [CrossRef] [PubMed]
- Alzaatreh, A.; Famoye, F.; Lee, C. Weibull-Pareto distribution and its applications. Commun. Stat.-Theory Methods 2013, 42, 1673–1691. [Google Scholar] [CrossRef]
- Muhammad, M.; Suleiman, M.I. The transmuted exponentiated U-quadratic distribution for lifetime modeling. Sohag J. Math. 2019, 6, 19–27. [Google Scholar]
- Muhammad, M.; Muhammad, I.; Yaya, A.M. The Kumaraswamy exponentiated U-quadratic distribution: Properties and application. Asian J. Probab. Stat. 2018, 1, 1–17. [Google Scholar] [CrossRef]
- Lai, C.; Xie, M.; Murthy, D. A modified Weibull distribution. IEEE Trans. Reliab. 2003, 52, 33–37. [Google Scholar] [CrossRef]
- Bebbington, M.; Lai, C.D.; Zitikis, R. A flexible Weibull extension. Reliab. Eng. Syst. Saf. 2007, 92, 719–726. [Google Scholar] [CrossRef]
- Ibrahim, M. The Kumaraswamy power function distribution. J. Stat. Appl. Probab 2017, 6, 81–90. [Google Scholar]
- Muhammad, M. Poisson-odd generalized exponential family of distributions: Theory and applications. Hacet. J. Math. Stat. 2016, 47, 1652–1670. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; dos Santos Brito, R. The beta power distribution. Braz. J. Probab. Stat. 2012, 26, 88–112. [Google Scholar]
- Bursa, N.; Gamze, O. The exponentiated Kumaraswamy-power function distribution. Hacet. J. Math. Stat. 2017, 46, 277–292. [Google Scholar] [CrossRef]
- Nadarajah, S.; Kotz, S. The beta exponential distribution. Reliab. Eng. Syst. Saf. 2006, 91, 689–697. [Google Scholar] [CrossRef]
- Barreto-Souza, W.; Santos, A.H.; Cordeiro, G.M. The beta generalized exponential distribution. J. Stat. Comput. Simul. 2010, 80, 159–172. [Google Scholar] [CrossRef]
- Shrahili, M.; Elbatal, I.; Muhammad, I.; Muhammad, M. Properties and applications of beta Erlang-truncated exponential distribution. J. Math. Comput. Sci. (JMCS) 2021, 22, 16–37. [Google Scholar] [CrossRef]
- Barreto-Souza, W.; Cribari-Neto, F. A generalization of the exponential-Poisson distribution. Stat. Probab. Lett. 2009, 79, 2493–2500. [Google Scholar] [CrossRef]
- Lemonte, A.J. A new exponential-type distribution with constant, decreasing, increasing, upside-down bathtub and bathtub-shaped failure rate function. Comput. Stat. Data Anal. 2013, 62, 149–170. [Google Scholar] [CrossRef]
- Kamal, M.; Alamri, O.A.; Ansari, S.I. A new extension of the Nadarajah Haghighi model: Mathematical properties and applications. J. Math. Comput. Sci. 2020, 10, 2891–2906. [Google Scholar]
- Okorie, I.; Akpanta, A.; Ohakwe, J.; Chikezie, D. The Extended Erlang-Truncated Exponential distribution: Properties and application to rainfall data. Heliyon 2017, 3, e00296. [Google Scholar] [CrossRef]
- Usman, R.M.; Haq, M.; Talib, J. Kumaraswamy half-logistic distribution: Properties and applications. J. Stat. Appl. Probab. 2017, 6, 597–609. [Google Scholar] [CrossRef]
- Adepoju, K.; Chukwu, O. Maximum likelihood estimation of the Kumaraswamy exponential distribution with applications. J. Mod. Appl. Stat. Methods 2015, 14, 18. [Google Scholar] [CrossRef]
- Cordeiro, G.M.; Ortega, E.M.; Nadarajah, S. The Kumaraswamy Weibull distribution with application to failure data. J. Frankl. Inst. 2010, 347, 1399–1429. [Google Scholar] [CrossRef]
- Muhammad, M.; Alshanbari, H.M.; Alanzi, A.R.; Liu, L.; Sami, W.; Chesneau, C.; Jamal, F. A new generator of probability models: The exponentiated sine-G family for lifetime studies. Entropy 2021, 23, 1394. [Google Scholar] [CrossRef] [PubMed]
- William, Q.M.; Escobar, L.A. Statistical Methods for Reliability Data; Wiley Interscience Publications: Hoboken, NJ, USA, 1998; p. 639. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Title | Cumulative Distribution Function | |
|---|---|---|
| 1 | Kumaraswamy-G (KwG) [20] | |
| 2 | Kumaraswamy Kw-G (KwKwG) [22] | |
| 3 | Kw Marshall–Olkin-G (KwMOG) [23] | |
| 4 | Kw transmuted-G (KwTG) [24] | |
| 5 | Kw Weibull-G (KwWG) [25] | , |
| 6 | Kw generalized Marshall–Olkin -G (KwgMOG) [26] | |
| 7 | Generalized Kw-G (GKwG) [27] | |
| 8 | Kw half logistic-G (KwHLG) [28] | |
| 9 | Exponentiated Kw-G (EKwG) [29] | |
| 10 | New Kw-G family (NKwG) [30] | |
| 11 | Kw Poisson-G (KwPG) [31] | |
| 12 | New flexible Kw-G family by [32] |
| 0.71768 | 1.03313 | 2.28219 | 6.83653 | 25.8867 | 118.4506 | (0.3, 1.41125) | |
| 0.61259 | 0.64795 | 1.01191 | 2.12487 | 5.64265 | 18.16074 | (03, 1.11913) | |
| 0.48557 | 0.35739 | 0.36531 | 0.48786 | 0.81371 | 1.63761 | (0.5, 0.44020) | |
| 0.41501 | 0.24510 | 0.19427 | 0.19756 | 0.24864 | 0.37611 | (0.7, 0.04891) | |
| 0.36200 | 0.16956 | 0.10021 | 0.07306 | 0.06440 | 0.06735 | (0.8, −0.28339) | |
| 0.31390 | 0.12234 | 0.05827 | 0.03343 | 0.22783 | 0.01821 | (0.9, −0.54607) | |
| 0.26369 | 0.08228 | 0.03011 | 0.01282 | 0.00630 | 0.00355 | (1.2, −0.91860) | |
| 0.17325 | 0.03102 | 0.00575 | 0.00110 | 0.00022 | 4.5132 | (1.5, −2.17380) | |
| 0.12747 | 0.01660 | 0.00221 | 0.00030 | 4.1846 | 5.0597 | (2.5, −2.78688) | |
| 0.10027 | 0.01019 | 0.00105 | 0.00011 | 1.3697 | 1.5809 | (4.0, −3.34023) |
| 2.86816 | 13.54189 | 65.44814 | 319.3925 | 1567.033 | 7714.550 | (0.3, 1.019132) | |
| 2.67845 | 11.85061 | 55.04053 | 260.9645 | 1251.6520 | 6047.708 | (0.3, 1.29516) | |
| 2.98179 | 14.18390 | 73.55873 | 396.6081 | 2186.6081 | 12,232.710 | (0.5, 1.56745) | |
| 3.655797 | 19.36484 | 112.9656 | 690.1417 | 4333.0080 | 27,701.230 | (0.6, 1.83527) | |
| 4.56824 | 28.82154 | 203.27880 | 1518.787 | 11,756.430 | 93,213.580 | (0.9, 2.17128) | |
| 5.012322 | 30.77091 | 211.8259 | 1567.821 | 12,194.33 | 98,314.690 | (0.95, 2.22128) | |
| 5.46455 | 34.2996 | 237.5096 | 1767.261 | 13,882.63 | 113,731.80 | (1.1, 2.12436) | |
| 5.88904 | 36.80876 | 242.8527 | 1682.792 | 12,190.180 | 91,929.880 | (1.2, 1.74467) | |
| 6.65158 | 45.90616 | 328.19940 | 2426.8060 | 18,530.43 | 145,889.60 | (1.5, 1.57082) | |
| 12.06492 | 145.8572 | 1766.8880 | 21,447.02 | 260,855.60 | 317,926.00 | (5, 0.504434) |
| Sample Size | Actual Values | Maximum Likelihood | Least Squares Estimation | Bayes Estimation | |||
|---|---|---|---|---|---|---|---|
| Parameter | AE | MSE (Bias) | AE | MSE (Bias) | AE | MSE (Bias) | |
| 30 | 1.8006 | 2.7013 (0.9001) | 1.7304 | 6.7979 (0.8303) | 1.4027 | 0.4654 (0.5027) | |
| 1.6046 | 2.9620 (1.1046) | 0.2263 | 0.7973 (−0.2734) | 0.4907 | 0.0483 (−0.0092) | ||
| 1.7107 | 0.8835 (0.2108) | 2.3014 | 2.8475 (0.8014) | 1.1071 | 0.3733 (−0.3929) | ||
| 0.4660 | 0.1726 (0.2660) | 0.9407 | 0.8815 (0.7408) | 1.3949 | 1.6274 (1.1949) | ||
| 50 | 1.0588 | 0.8541 (0.1588) | 1.5768 | 3.8842 (0.6768) | 1.3716 | 0.4396 (0.4716) | |
| 1.4082 | 2.8272 (0.9081) | 0.2108 | 0.7341 (−0.2892) | 0.4499 | 0.0349 (−0.0501) | ||
| 1.9599 | 0.7059 (0.4599) | 2.6065 | 2.7268 (1.1065) | 1.0137 | 0.3641 (−0.4863) | ||
| 0.3119 | 0.0983 (0.1186) | 0.7612 | 0.5395 (0.5612) | 1.3869 | 1.5649 (1.1869) | ||
| 100 | 1.1416 | 0.5249 (0.2415) | 1.0754 | 0.6415 (0.1754) | 1.2564 | 0.3129 (0.3564) | |
| 1.1579 | 1.3741 (0.6579) | 0.9353 | 0.6362 (0.4353) | 0.4496 | 0.0222 (−0.0504) | ||
| 1.6213 | 0.3529 (0.1213) | 1.8049 | 1.0281 (0.3049) | 0.9662 | 0.3581 (−0.5339) | ||
| 0.3231 | 0.0657 (0.1231) | 0.3509 | 0.1247 (0.1509) | 1.3065 | 1.3316 (1.1065) | ||
| 200 | 1.2736 | 0.5044 (0.3736) | 1.2862 | 0.4045 (0.3862) | 1.1489 | 0.1719 (0.2488) | |
| 0.6213 | 1.0565 (0.1213) | 0.1695 | 0.1633 (−0.3305) | 0.4668 | 0.0143 (−0.0333) | ||
| 1.4605 | 0.2436 (−0.0395) | 3.0593 | 1.0173 (1.5593) | 0.9356 | 0.3458 (−0.5644) | ||
| 0.3912 | 0.0577 (0.1912) | 0.5846 | 0.1028 (0.3846) | 1.2134 | 1.0191 (1.0134) | ||
| 300 | 0.9245 | 0.2123 (0.0245) | 1.3457 | 0.3252 (0.4457) | 1.0740 | 0.0175 (0.1746) | |
| 0.8167 | 1.0143 (0.3167) | 0.1575 | 0.1538 (−0.3425) | 0.4802 | 0.0071 (−0.0198) | ||
| 1.5928 | 0.1516 (0.0928) | 2.6932 | 1.0119 (1.4466) | 0.9152 | 0.3137 (−0.5848) | ||
| 0.2462 | 0.0322 (0.0462) | 0.3140 | 0.1011 (0.3934) | 0.1620 | 0.9664 (0.9621) | ||
| 30 | 1.2599 | 1.6494 (0.4599) | 1.0549 | 2.0909 (0.2549) | 1.4039 | 0.4689 (0.6393) | |
| 3.1148 | 6.3529 (2.5148) | 0.3145 | 0.9258 (−0.2855) | 0.7568 | 0.1265 (0.1568) | ||
| 1.7215 | 1.2941 (0.4215) | 2.1351 | 2.4326 (0.8351) | 1.1430 | 0.1724 (−0.1569) | ||
| 0.5408 | 0.8770 (0.2408) | 1.4441 | 2.0211 (1.1441) | 1.0523 | 1.0136 (0.7523) | ||
| 50 | 0.8026 | 0.6147 (0.0027) | 1.0165 | 1.0591 (0.2165) | 1.3538 | 0.4213 (0.5538) | |
| 0.8751 | 2.7323 (0.2751) | 0.2626 | 0.3763 (−0.3375) | 0.6455 | 0.1006 (0.0455) | ||
| 1.8551 | 1.2417 (0.5551) | 1.9444 | 1.8305 (0.6444) | 1.1106 | 0.1242 (−0.1439) | ||
| 0.7767 | 0.7698 (0.4767) | 1.4506 | 1.2177 (1.1506) | 1.2768 | 1.0119 (0.9768) | ||
| 100 | 1.0189 | 0.2508 (0.2189) | 0.8088 | 0.4905 (0.0088) | 1.3493 | 0.4201 (0.5493) | |
| 0.5024 | 1.4239 (−0.0976) | 1.4947 | 0.3712 (0.8947) | 0.5079 | 0.0660 (−0.0921) | ||
| 1.3348 | 0.2385 (0.0348) | 1.6855 | 1.1491 (0.3856) | 1.0849 | 0.1065 (−0.2152) | ||
| 0.8522 | 0.4676 (0.5522) | 0.4497 | 0.2703 (0.1496) | 1.5119 | 1.0103 (1.2111) | ||
| 200 | 0.7443 | 0.2100 (−0.0557) | 1.0069 | 0.4091 (0.2069) | 1.3226 | 0.3925 (0.5226) | |
| 0.9253 | 1.3761 (0.3253) | 0.2773 | 0.1868 (−0.3227) | 0.4519 | 0.0048 (−0.1481) | ||
| 1.5262 | 0.2351 (0.2262) | 1.6212 | 0.7274 (0.3212) | 1.0901 | 0.1057 (−0.2099) | ||
| 0.4672 | 0.1342 (0.1672) | 1.3094 | 0.1977 (1.0093) | 1.5502 | 1.0100 (1.2503) | ||
| 300 | 0.8393 | 0.1383 (0.0394) | 0.9956 | 0.3129 (0.1956) | 1.3172 | 0.3789 (0.5172) | |
| 0.5177 | 1.1733 (−0.0080) | 0.3118 | 0.1798 (−0.2882) | 0.4432 | 0.0041 (−0.1567) | ||
| 1.3359 | 0.2073 (0.0359) | 1.5242 | 0.4723 (0.2242) | 1.0648 | 0.1036 (−0.2352) | ||
| 0.3278 | 0.1282 (0.3279) | 0.5912 | 0.1223 (0.7912) | 0.5244 | 1.0031 (1.2244) | ||
| 30 | 3.6849 | 6.9051 (2.7849) | 3.3102 | 4.1841 (2.4102) | 1.3901 | 0.4901 (0.4920) | |
| 0.7941 | 5.0230 (−0.0059) | 0.2286 | 0.6271 (−0.5713) | 0.4622 | 0.1470 (−0.3377) | ||
| 1.3163 | 1.8718 (−0.2837) | 1.3882 | 1.1080 (−0.2118) | 1.0320 | 0.4988 (−0.679) | ||
| 0.6934 | 0.5599 (0.5934) | 1.2924 | 1.8682 (1.1924) | 1.3599 | 1.7374 (1.2599) | ||
| 50 | 1.3867 | 1.8839 (0.4868) | 2.5043 | 2.2238 (2.0421) | 1.2972 | 0.4145 (0.3972) | |
| 1.1378 | 1.7544 (0.9379) | 0.2289 | 0.5851 (−0.5711) | 0.4519 | 0.1435 (−0.3480) | ||
| 2.1052 | 1.8452 (0.5052) | 1.3469 | 0.8534 (−0.2531) | 0.9595 | 0.4905 (−0.6404) | ||
| 0.2209 | 0.0599 (0.1209) | 0.2657 | 1.8499 (1.1657) | 0.2981 | 1.5494 (1.1981) | ||
| 100 | 1.5896 | 1.6266 (0.6596) | 3.9471 | 1.6999 (0.0471) | 1.1788 | 0.2715 (0.2788) | |
| 0.9147 | 1.6862 (0.1147) | 0.2309 | 0.5715 (−0.5691) | 0.4668 | 0.1246 (−0.3332) | ||
| 1.7741 | 0.5433 (0.1741) | 1.3780 | 0.7239 (−0.2219) | 0.9183 | 0.4045 (−0.6817) | ||
| 0.2895 | 0.0552 (0.1896) | 0.2221 | 1.8218 (1.1221) | 0.2037 | 1.2743 (1.1037) | ||
| 200 | 2.657 | 1.0958 (1.7578) | 3.9653 | 1.5652 (1.0652) | 1.0464 | 0.0810 (0.1464) | |
| 0.3649 | 0.8503 (−0.4351) | 0.5164 | 0.4247 (−0.5836) | 0.4946 | 0.0966 (−0.3054) | ||
| 1.1009 | 0.3560 (−0.4991) | 1.3398 | 0.6188 (−0.2616) | 0.8989 | 0.3042 (−0.7010) | ||
| 0.5457 | 0.0402 (0.4457) | 0.1476 | 1.6308 (1.0476) | 0.1285 | 1.0772 (1.0285) | ||
| 300 | 2.1815 | 1.0396 (1.2815) | 3.9173 | 1.4341 (1.0173) | 1.0106 | 0.0232 (0.1106) | |
| 0.4289 | 0.6126 (−0.3710) | 0.5359 | 0.3921 (−0.5641) | 0.4976 | 0.0922 (−0.3024) | ||
| 1.2506 | 0.2827 (−0.3494) | 1.3718 | 0.6034 (−0.2282) | 0.9008 | 0.2899 (−0.6992) | ||
| 0.4141 | 0.0337 (0.3141) | 0.0553 | 1.3245 (0.9053) | 0.1057 | 1.0148 (1.0057) | ||
| Sample Size | Actual Values | Maximum Likelihood | Least Squares Estimation | Bayes Estimation | |||
|---|---|---|---|---|---|---|---|
| Parameter | AE | MSE (Bias) | AE | MSE (Bias) | AE | MSE (Bias) | |
| 30 | 0.3817 | 0.9681 (−0.5182) | 0.6761 | 0.6955 (−0.2239) | 1.0351 | 0.0433 (0.1351) | |
| 0.4463 | 1.9703 (−0.4537) | 0.8107 | 2.1919 (−0.0893) | 0.4917 | 0.1717 (−0.4083) | ||
| 1.6751 | 1.2806 (0.8750) | 0.8272 | 0.4846 (0.0272) | 0.9006 | 0.0335 (0.1006) | ||
| 0.3460 | 0.1252 (0.2461) | 0.9111 | 0.8984 (0.8111) | 0.3430 | 1.1152 (1.0430) | ||
| 50 | 0.5165 | 0.9570 (−0.4835) | 0.6052 | 0.4416 (−0.2948) | 1.0020 | 0.0116 (0.1019) | |
| 0.8511 | 1.2601 (−0.0489) | 0.4769 | 2.0619 (−0.4231) | 0.4989 | 0.1619 (−0.4016) | ||
| 1.5370 | 1.1341 (0.7371) | 0.7443 | 0.1975 (−0.0557) | 0.9003 | 0.0111 (0.1003) | ||
| 0.2811 | 0.0612 (0.1811) | 0.0564 | 0.8817 (0.8564) | 0.5056 | 1.0144 (1.0056) | ||
| 100 | 0.3895 | 0.4320 (−0.5105) | 0.4918 | 0.3323 (−0.4082) | 1.0001 | 0.0101 (0.1001) | |
| 0.4533 | 1.1413 (−0.4467) | 0.2570 | 1.5292 (−0.6429) | 0.4999 | 0.1601 (−0.4007) | ||
| 1.4027 | 0.8709 (0.6027) | 0.7718 | 0.1407 (−0.0283) | 0.8999 | 0.0099 (0.0999) | ||
| 0.2649 | 0.0433 (0.1649) | 0.9504 | 0.8489 (0.8504) | 0.1900 | 1.0002 (1.0001) | ||
| 200 | 0.8821 | 0.3965 (−0.5179) | 0.4250 | 0.2890 (−0.4749) | 1.2697 | 0.0036 (0.3697) | |
| 0.4246 | 1.1347 (−0.6754) | 0.8399 | 0.6607 (−0.7600) | 0.7590 | 0.0933 (−0.1409) | ||
| 1.5257 | 0.4936 (0.7256) | 0.7760 | 0.0719 (−0.0239) | 0.8619 | 0.0086 (0.0619) | ||
| 0.2368 | 0.0206 (0.1168) | 0.1919 | 0.8153 (0.8919) | 1.0169 | 0.8727 (0.9169) | ||
| 300 | 0.9498 | 0.3642 (−0.4501) | 0.8025 | 0.2800 (−0.4975) | 1.2561 | 0.0033 (0.3561) | |
| 0.9639 | 1.0483 (−0.5036) | 0.6369 | 0.6491 (−0.7631) | 0.7566 | 0.0963 (−0.1434) | ||
| 1.2168 | 0.4162 (0.4168) | 0.8055 | 0.0689 (0.0056) | 0.8825 | 0.0084 (0.6246) | ||
| 0.2316 | 0.0207 (0.1316) | 0.0965 | 0.8151 (0.8655) | 0.0980 | 0.8633 (0.9098) | ||
| 30 | 1.743 | 1.9704 (0.0256) | 1.3804 | 2.9631 (0.1804) | 1.3034 | 0.0282 (0.1034) | |
| 1.2735 | 1.4076 (1.6213) | 2.9285 | 1.3845 (1.4285) | 1.3702 | 0.9756 (0.8702) | ||
| 3.1076 | 1.6792 (1.3076) | 3.1377 | 1.8231 (1.3377) | 1.4807 | 0.1295 (−0.3193) | ||
| 1.2450 | 1.5867 (−0.2549) | 1.9838 | 1.2011 (0.9034) | 0.9034 | 0.3688 (−0.5966) | ||
| 50 | 1.6408 | 1.8623 (0.4408) | 1.3028 | 2.8544 (0.1028) | 1.2630 | 0.0280 (0.0629) | |
| 1.6196 | 1.3254 (0.1196) | 1.9128 | 1.2836 (1.4128) | 1.3304 | 0.7124 (0.8304) | ||
| 2.5037 | 1.2487 (0.7038) | 2.8896 | 1.7275 (1.0896) | 1.4823 | 0.1278 (−0.3178) | ||
| 1.9977 | 1.5511 (0.4977) | 1.7057 | 1.0768 (0.2057) | 0.9057 | 0.3680 (−0.5945) | ||
| 100 | 1.3408 | 1.4408 (0.2408) | 1.2354 | 1.4042 (0.0354) | 1.2025 | 0.0214 (0.0025) | |
| 1.3463 | 1.2978 (0.8463) | 1.4629 | 1.1302 (0.9629) | 1.2389 | 0.5877 (0.7389) | ||
| 2.2718 | 1.1064 (0.4718) | 2.6212 | 0.8195 (0.8212) | 1.5189 | 0.1085 (−0.2812) | ||
| 1.8946 | 1.0894 (0.3946) | 1.5977 | 0.5677 (0.0977) | 0.9187 | 0.3131 (−0.5813) | ||
| 200 | 1.4169 | 1.1409 (0.2167) | 1.2822 | 1.1884 (0.0822) | 2.1391 | 0.0108 (−0.0609) | |
| 0.9447 | 1.1756 (0.4442) | 1.1759 | 1.0702 (0.6759) | 1.0670 | 0.3774 (0.5671) | ||
| 2.0925 | 0.6398 (0.2925) | 2.3519 | 0.3334 (0.5519) | 1.5915 | 0.0796 (−0.2085) | ||
| 1.8495 | 1.0294 (0.3495) | 1.6843 | 0.5305 (0.1843) | 0.9908 | 0.3082 (−0.5093) | ||
| 300 | 1.3656 | 1.1399 (0.1656) | 1.3682 | 0.5389 (0.1682) | 1.1149 | 0.0104 (−0.0851) | |
| 0.8583 | 1.1012 (0.3583) | 1.0543 | 1.0513 (0.5542) | 0.9693 | 0.2727 (0.4693) | ||
| 2.0026 | 0.5430 (0.2026) | 2.2385 | 0.1725 (0.4385) | 1.6363 | 0.0634 (−0.1637) | ||
| 1.7865 | 1.0184 (0.2865) | 1.7890 | 0.4505 (0.2894) | 1.0262 | 0.3079 (−0.4738) | ||
| 30 | 1.7701 | 2.6890 (1.5491) | 1.6335 | 1.4435 (0.3335) | 1.2880 | 0.0163 (−0.0119) | |
| 1.0233 | 1.3059 (1.5331) | 0.9805 | 1.9453 (1.1056) | 1.0440 | 0.5653 (0.7406) | ||
| 1.4934 | 1.8305 (−0.065) | 1.6488 | 1.5479 (1.1488) | 1.4599 | 0.0277 (−0.0401) | ||
| 1.0851 | 1.9755 (1.5851) | 1.4190 | 1.4532 (0.6119) | 0.9538 | 0.3060 (−0.5462) | ||
| 50 | 1.7819 | 2.6289 (0.4819) | 1.5130 | 1.4428 (0.2130) | 1.2487 | 0.0108 (−0.0513) | |
| 1.3448 | 1.2257 (1.6448) | 2.6199 | 1.7703 (1.9199) | 1.4130 | 0.5307 (0.7130) | ||
| 2.0436 | 1.7296 (0.5436) | 2.4146 | 1.1699 (0.9146) | 1.4379 | 0.0241 (−0.0621) | ||
| 2.4704 | 1.7845 (0.9704) | 2.0158 | 1.4152 (0.5158) | 0.9584 | 0.3034 (−0.5406) | ||
| 100 | 1.4670 | 1.6288 (0.1670) | 1.4288 | 1.2613 (0.1287) | 1.2057 | 0.0103 (−0.0943) | |
| 2.3552 | 1.1633 (1.6552) | 1.7995 | 1.5024 (1.0995) | 1.3747 | 0.4955 (0.6747) | ||
| 1.8117 | 1.2098 (0.3117) | 2.0658 | 1.0073 (0.5657) | 1.4328 | 0.0227 (−0.0672) | ||
| 2.0452 | 1.6784 (0.5452) | 2.0116 | 1.3612 (0.5126) | 0.9522 | 0.3008 (−0.5478) | ||
| 200 | 1.7226 | 1.3829 (0.4226) | 1.3905 | 1.0983 (0.0903) | 1.1658 | 0.0101 (−0.1343) | |
| 1.2389 | 1.1065 (0.5389) | 1.5357 | 1.1174 (0.8357) | 1.2681 | 0.3853 (0.5681) | ||
| 1.5232 | 0.7898 (0.0232) | 1.8928 | 0.9315 (0.3928) | 1.4646 | 0.0221 (−0.0356) | ||
| 2.4740 | 1.6092 (0.9740) | 1.9057 | 1.2091 (0.4058) | 0.9821 | 0.3001 (−0.5179) | ||
| 300 | 1.4445 | 1.1039 (0.1445) | 1.3748 | 1.0700 (0.0748) | 1.1678 | 0.0100 (−0.1322) | |
| 1.0345 | 1.0288 (0.8345) | 1.4435 | 1.0874 (0.7435) | 1.1725 | 0.1886 (0.4725) | ||
| 1.6759 | 0.4200 (0.1758) | 1.7882 | 0.6083 (0.2882) | 1.1180 | 0.0215 (−0.0195) | ||
| 2.0199 | 0.5198 (0.5199) | 1.8745 | 0.3745 (0.3745) | 1.4170 | 0.2615 (−0.4583) | ||
| Model | ||||||||
|---|---|---|---|---|---|---|---|---|
| NEKwU | − | − | − | − | ||||
| KwP | − | − | − | 301 | − | |||
| EKwP | − | − | − | |||||
| KwEUq | − | − | − | |||||
| POEU | − | − | − | − | − | |||
| BU | − | − | − | − | − | |||
| WP | − | − | − | − | − | |||
| TEUq | 300 | − | − | − | − | |||
| MW | − | − | − | − | − | |||
| FW | − | − | − | − | − | − |
| Model | L | AIC | BIC | CAIC | KS | AD | CvM |
|---|---|---|---|---|---|---|---|
| NEKwU | |||||||
| KwP | |||||||
| EKwP | |||||||
| KwEUq | |||||||
| POEU | |||||||
| BU | |||||||
| WP | |||||||
| TEUq | |||||||
| MW | |||||||
| FW |
| Model | |||||||
|---|---|---|---|---|---|---|---|
| NEKwE | − | − | − | ||||
| KwE | − | − | − | − | |||
| KwHL | − | − | − | − | |||
| KwW | − | − | − | ||||
| EKwE | − | − | − | ||||
| EKwW | − | − | |||||
| BE | − | − | − | − | |||
| BGE | − | − | − | ||||
| BETE | − | − | − | ||||
| GE | − | − | − | − | − | ||
| GEP | − | − | − | − | |||
| ENH | − | − | − | − | |||
| EETE | − | − | − | − | |||
| ESE | − | − | − | − | − | ||
| ExCE | − | − | − | − | − | ||
| E | − | − | − | − | − | − |
| Model | L | AIC | BIC | CAIC | KS | AD | CvM |
|---|---|---|---|---|---|---|---|
| NEKwE | |||||||
| KwE | |||||||
| KwHL | |||||||
| KwW | |||||||
| EKwE | |||||||
| EKwW | |||||||
| BE | |||||||
| BGE | |||||||
| BETE | |||||||
| GE | |||||||
| GEP | |||||||
| ENH | |||||||
| EETE | |||||||
| ESE | |||||||
| ExCE | |||||||
| E |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abbas, S.; Muhammad, M.; Jamal, F.; Chesneau, C.; Muhammad, I.; Bouchane, M. A New Extension of the Kumaraswamy Generated Family of Distributions with Applications to Real Data. Computation 2023, 11, 26. https://doi.org/10.3390/computation11020026
Abbas S, Muhammad M, Jamal F, Chesneau C, Muhammad I, Bouchane M. A New Extension of the Kumaraswamy Generated Family of Distributions with Applications to Real Data. Computation. 2023; 11(2):26. https://doi.org/10.3390/computation11020026
Chicago/Turabian StyleAbbas, Salma, Mustapha Muhammad, Farrukh Jamal, Christophe Chesneau, Isyaku Muhammad, and Mouna Bouchane. 2023. "A New Extension of the Kumaraswamy Generated Family of Distributions with Applications to Real Data" Computation 11, no. 2: 26. https://doi.org/10.3390/computation11020026